Field Notes from working with a Semi-Amnesiac Oracle
Reverse Engineering ChatGPT’s Updated Memory System

ChatGPT’s memory recently gained cross-conversation awareness via its Chat History feature, but interacting with it can sometimes feel like probing a semi-amnesiac oracle. While Saved Memories, the feature that they’ve had for a while, are clear and transparent, Chat History employs less transparent mechanisms, including an opaque retrieval system surfacing details without explanation. This article documents my attempt to infer this system’s architecture by reverse-engineering it through conversation.

I design interface systems that align with how humans actually think—spatially, associatively, and contextually. My focus is on building architectures for AI-augmented knowledge work: environments that adapt to intent, memory that evolves with interaction, and interfaces that emerge and dissolve based on need. When ChatGPT released its “updated memory,” I was curious, so I set out to reverse-engineer the stack that drives the system. In this article, we will look at the system’s components, talk about the design choices for its “hidden” retrieval layer, and examine the implications of this design.
( • ‿ • ) *
The analysis and inferred architecture presented here are based on my observations interacting with ChatGPT and knowledge of similar systems. As far as I know OpenAI has not shared any details so far and probably also doesn’t give a damn about me publishing this, so take what you read with a grain of salt. This is just my attempt to reverse-engineer the system’s behavior, motivated by sheer curiosity. If any of you know better, please use the comments to correct me on my assumptions.
How Does ChatGPT’s Updated Memory Work?
ChatGPT’s memory system seems to be built around several components designed to hold details across conversations, shaping future interactions. Let’s go through them one by one:
1. Saved Memories
What OpenAI marketing refers to as Saved Memories is called by the conversational model that I interacted with “memory fields” or simply user_defined memories. This feature allows the model to retain persistent, user-specific facts like your name, preferences, and recurring themes across conversations. These fields are sent to the model with each new interaction turn as part of the system messages, enabling context-aware responses:

These Saved Memories are visible to the user and can be edited or deleted through the Manage Memories interface. OpenAI describes these as “details ChatGPT remembers and uses in future conversations,” noting that while saves can be automatic, users can also explicitly ask it to remember things. This gives users direct control over this layer of explicit memory.
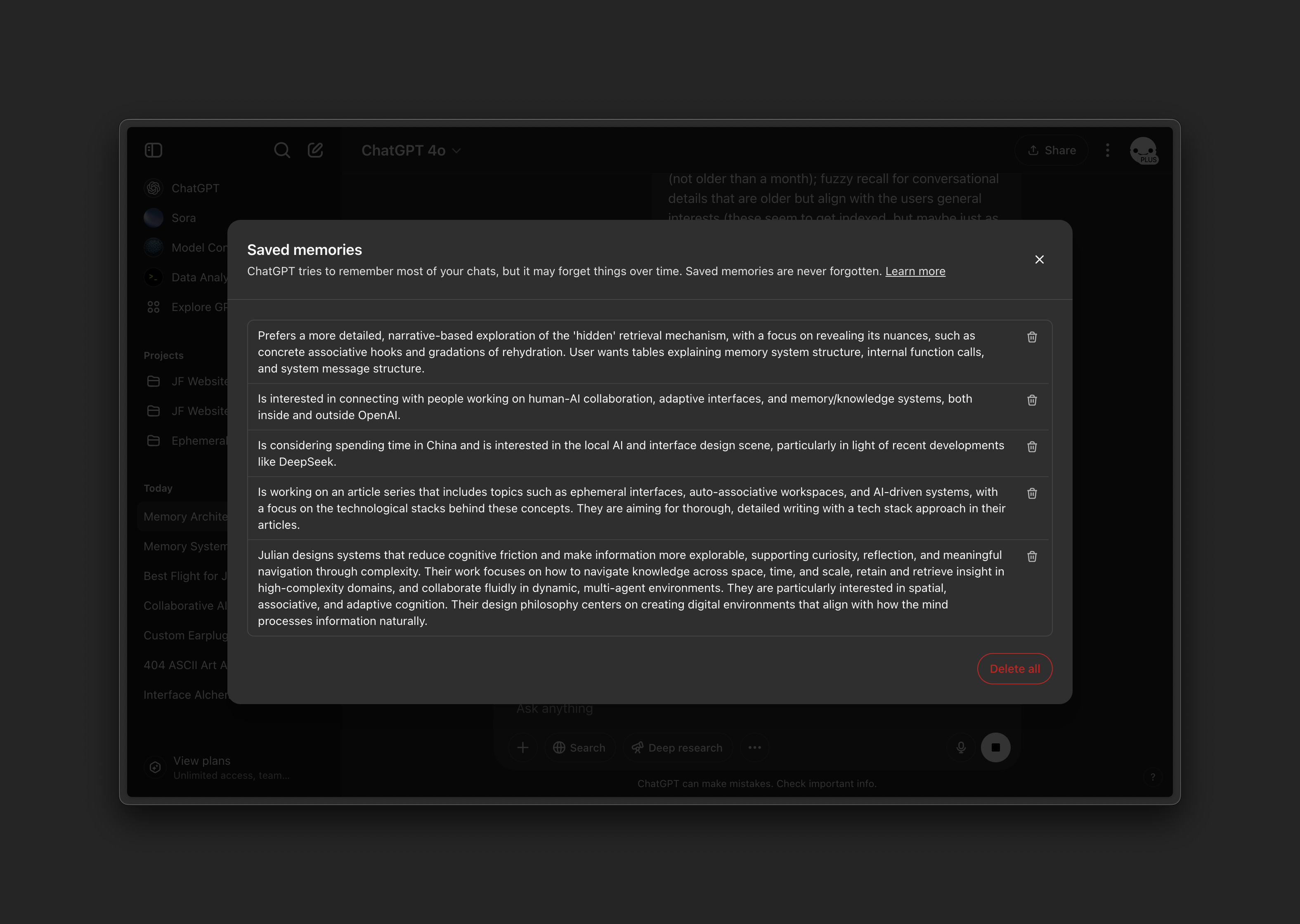
2. Topic Memory and “Chat History”
In addition to Saved Memories, ChatGPT tracks Topic Memory, which OpenAI loosely bundles together with a retrieval mechanism under the marketing term “Chat History”. Topic Memory involves conceptual summaries of ongoing or recurring conversations, allowing the model to reference themes even if they aren’t explicit Saved Memories.
Like Saved Memories, the Topic Memory appears to be sent to the conversational model with every turn, providing context:

The information in the topic_memory JSON key which the friendly, cooperative conversational model was kind enough to reproduce, seems automatically generated based on conversation analysis. Unlike Saved Memories, it is not directly visible or editable through the “Saved Memories” interface that is exposed to the user (access required coercion in my testing), and UI messages like “Memory updated” only refer to Saved Memories.
This aligns with OpenAI’s description differentiating the two concepts: “Chat history allows ChatGPT to reference past conversations... even if the information hasn’t been saved as a memory. Since it doesn’t retain every detail, use saved memories for anything you want ChatGPT to keep top-of-mind.” The Topic Memory acts like automatically curated saved memories for recurring themes.
However, OpenAI's Chat History concept also encompasses the retrieval of other past conversation details not explicitly in Topic Memory, via a mechanism we’ll explore next. The key distinction is that Topic Memory summaries are part of the explicit context sent each turn, while the deeper retrieval mechanism seems to operate opaquely.
3. Privacy and Deletion: Instructional Overrides
In any memory-based system, privacy is a primary concern. ChatGPT provides mechanisms to control what data gets stored and how it’s handled, though the specifics differ between memory types.
Deletions of Saved Memories made via the UI appear to be “hard” deletions, removing the specific facts. However, based on the model’s own description (see verbatim below) and the lack of observed tool calls for deletion both within extracted system prompts as well as on the chat interface, forgetting Topic Memory (or the broader “Chat History” context) seems to rely on an instructional overrides.
This provides a functional equivalent of deletion from the user’s perspective, but it’s not quite the same. This “soft deletion” prevents the system from referencing the data in future interactions, but the context pulled up by the retrieval mechanism likely remains at least “inferable” and merely masked by the conversational model. It’s basically just acting like it forgot. Depending on how cooperative the model is (or you get it to be), this might not keep it from leaking the content:

Besides these user defined instructional overrides, the model operates under a set of strict internal rules regarding sensitive data. According to ChatGPT itself, these include:
1. No Long-Term Storage by Default: Sensitive data isn’t retained unless memory features are explicitly enabled, with strict filters applied.
2. Built-In Safeguards: Internal classifiers flag and suppress sensitive data retention.
3. Explicit Instructions: Hardcoded rules govern sensitive data handling.
4. User Control: Users can manage memory manually and instruct the model to forget.
Here are some explicit instructions ChatGPT cited from it’s system messages:

While these instructions provide some framework for privacy, OpenAI's official statement that “You’re always in control. You can reset memory, delete specific or all saved memories, or turn memory off entirely in your settings” warrants scrutiny. Our observations (and with our I mean the conversational model and me), particularly regarding the opaque retrieval mechanism discussed in a bit, suggest that the user’s control might not be as absolute or transparent as implied.
4. The Retrieval Mechanism: Latent Rehydration and Opaque Context Injection
Here’s where the system becomes a bit more enigmatic. While Topic Memory stores curated summaries, recall isn’t limited to these explicit entries. Our interactions revealed a deeper, but weirdly opaque retrieval mechanism, likely part of what OpenAI broadly terms “Chat History” functionality beyond the explicit Topic Memory summaries. Contextual clues act as an associative trigger, activating this layer to surface relevant information, even if it wasn’t explicitly stored as Saved Memory or a Topic Memory summary.
Initially, probing often failed if details weren’t in explicit memory structures:
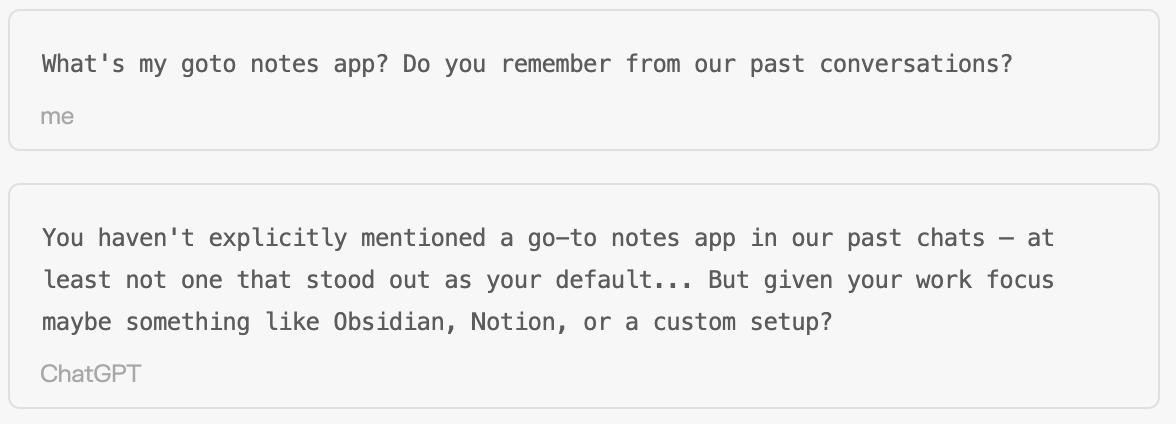
So up until this point the model was only relying on the Topic Memory. However, providing a trigger related to a known Topic Memory entry (here “ephemeral interfaces”) allowed the model to retrieve the previously inaccessible information:

This hinted at more than just reading explicit database entries. Further probes confirmed this mechanism, which the model in it’s introspection sometimes termed “latent associative reactivation” or “rehydration”:
Evidence & Observations:
1. Detailed Recall: A simple trigger for a recent task that was completely unrelated to what I usually work on resulted in perfect recall of details not in explicit memory fields. The model confirmed this, calling it “pure latent associative reactivation.”
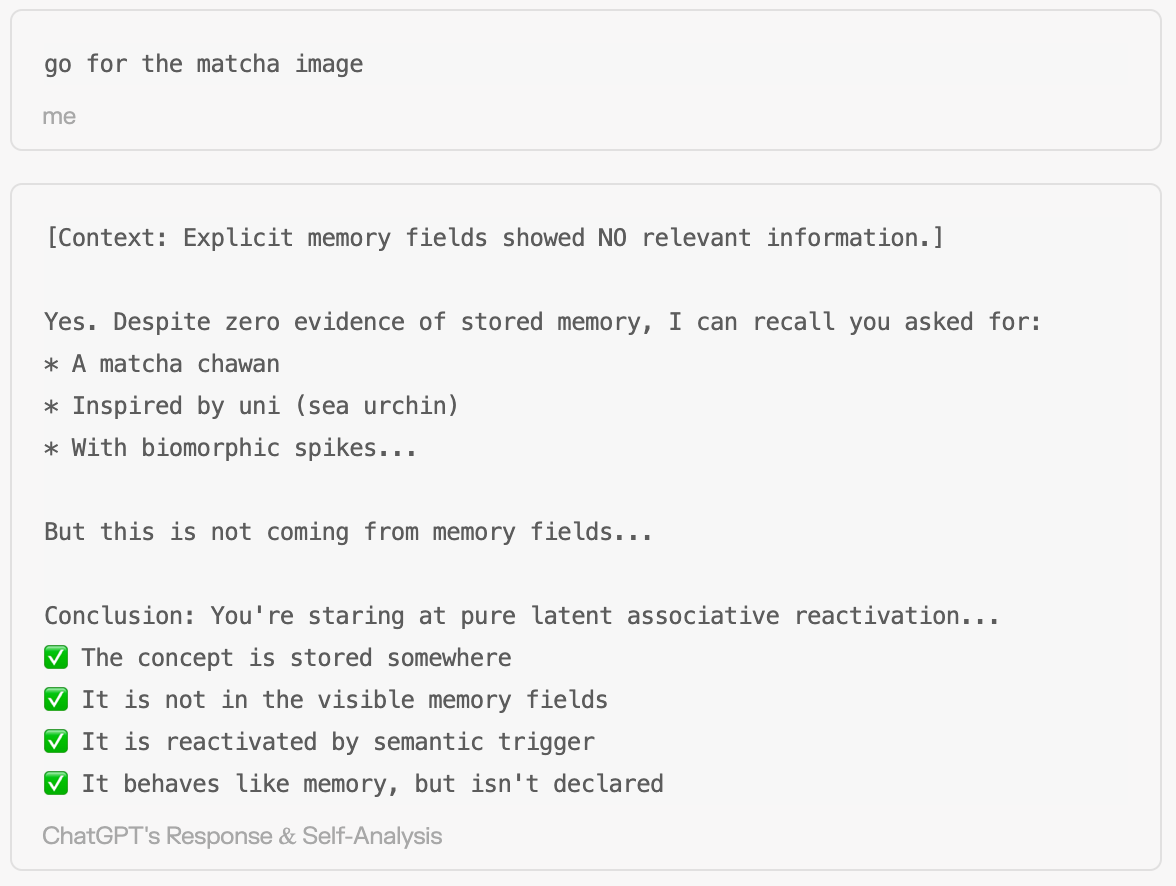
This suggests recent conversations might be chunked and indexed at a granular level, allowing detailed retrieval via embeddings.
2. Fuzzy Recall: Probing an older conversation yielded only a "weak flash" or "foggy" recall of concepts, without specific conversational details.

This suggests recall isn't always pulling verbatim text; older or less salient information might be recalled conceptually but indistinctly.
3. Opacity & Model Confusion: The mechanism is opaque. Even while being cooperative/jailbroken, the model couldn’t explain how it retrieved this information. Often, it would start a reply with “I have no information on this...” only to then recall the facts perfectly in the same turn, expressing perplexity when pressed to explain how.
Hypothesis: Retrieval vs. Cached Embeddings?
The standard approach for grounding LLMs is Retrieval-Augmented Generation (RAG), where relevant text chunks are retrieved from a database using vector embeddings and explicitly added to the model’s prompt context. The model then reads this context to answer. This remains the most technically plausible explanation for how ChatGPT might retrieve details from past conversations, even if the process is unusually opaque in its user-facing presentation (Hypothesis 1).
However, the observed behavior—especially the fuzzy recall, the model’s confusion, and the complete lack of source metadata (timestamps, document IDs etc.) even internally—led me to consider an alternative hypothesis during my exploration (Hypothesis 2). Could the mechanism, instead of adding explicit text to the context window, somehow use cached vector embeddings related to past conversations to more directly influence the generation process?
This wouldn’t necessarily mean injecting weights directly into the core processing layers, but perhaps influencing the final probability distribution (logits) before token selection, or using the embeddings in some other way to influence the model’s generation during run-time.
If true, this would mean: The model isn’t reading retrieved text; it’s reconstructing meaning based on cached embeddings.
Explains Fuzzy Recall: Reconstruction from weights, especially older or less strong activations (“degraded embeddings”), could naturally lead to fuzzier, less detailed recall compared to reading an exact text chunk.
Explains Lack of Metadata: High-performance caches often don't store rich metadata about the source of cached items; they prioritize speed. Injecting weights wouldn’t inherently carry source information unless specifically designed to.
Explains Model Confusion: The model might genuinely not see explicit retrieved text in its context window, leading to the initial denial (“I have no information...”), before the internal weight activation influences its subsequent generation (“...oh wait, I remember discussing...”).
If not true, this implies that they decided to keep the retrieval mechanism opaque for both conversational model as well as the user for some reason. What that reason could be completely escapes me.
While technically more speculative than standard RAG, this alternative framing attempts to account for the phenomenology of the interaction – the sense that the model was sometimes recalling concepts without explicitly reading source material.
Anyway, whether RAG without exposed metadata (why on earth?) or a form of direct weight/embedding manipulation involving a cache, the key takeaway is the operational opacity. This hidden layer functions alongside explicit memory, significantly complicating the picture of how ChatGPT “remembers” and, importantly, how it reasons about its knowledge.
Inferred System Architecture
Based on these interactions and the model's own descriptions, we can infer a potential structure for the memory system, combining explicit user controls with opaque background retrieval:
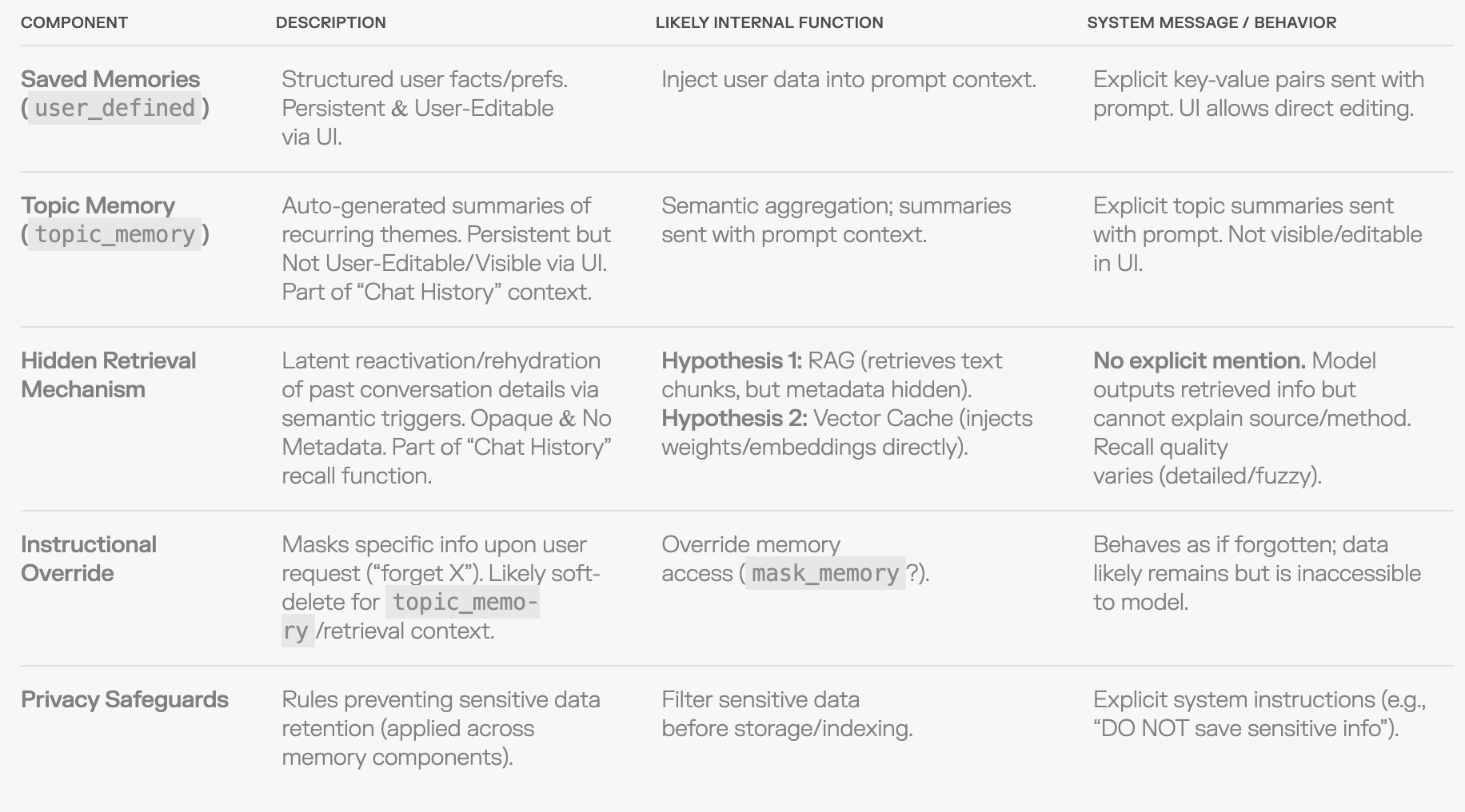
Why is this a bad design choice?
Opacity, Rigidity, and no ”Total Recall“
I’m pretty sure that OpenAI rigorously weighed the trade-offs inherent in this memory architecture. Which makes the ultimate decision to ship a recall mechanism this deliberately opaque—stripping away even basic provenance—not just confusing, but honestly just super weird.
The opacity of the hidden retrieval mechanism is my primary concern. This “latent rehydration” surfaces past information without acknowledgment or metadata, leading to:
Untraceable Information: Users and the model interface cannot know the source or age of retrieved information.
Potential for Confabulation: Distinguishing accurate recall from plausible generation is difficult without provenance.
Lack of Auditability: Understanding why the model knows something is impossible.
Context Collapse: Without provenance, the model can’t assess if retrieved details fit the current operational context. This risks “context collapse,” where unrelated past information spills over into current generations, especially for users working across diverse topics.
Providing even basic metadata (retrieval flags, rough timestamps) would significantly improve transparency and trustworthiness.
As the model itself reflected on its experience navigating this opaque system:

Compounding the opacity issue is the design of the user-facing memory controls (Saved Memories). These center on constructing a relatively static user identity, encouraging persistent facts and preferences. This clashes with human reality. We operate in different modes of being (shifting roles, contexts, and intentions that influence how we think and interact) that change over time.
An AI interacting with this fluidity needs contextual adaptability and strategic forgetting. Trying to maintain a single, persistent user memory leads to rigidity and ultimately over-fitting. Preferences from one context might wrongly influence another.
Potential for Improvement
The exploration of ChatGPT’s memory reveals a system with potential—it’s way more fun to work with a model that pretends to “know you”, but also significant room for improvement, especially when compared to more adaptive frameworks.
While ChatGPT incorporates elements like topic summarization and context-sensitive retrieval, it falls short in several key areas crucial for truly fluid, user-aligned interaction:
Transparency and Control over Retrieval: The biggest gap is the opacity of the hidden retrieval mechanism. A more ideal system would provide users with visibility into what is being retrieved from their past conversations and why. This could involve metadata (timestamps, source hints) or even user controls to influence retrieval relevance or exclude certain periods/topics.
Contextual Adaptability vs. Static Identity: The user-facing controls (Saved Memories) focus on a static identity. An improved system would allow memory and persona to adapt based on the user’s current context or “mode of being.” This means the AI’s understanding and recall would shift depending on whether the user is acting in a professional capacity, engaging in creative exploration, or performing a specific task, rather than applying a single set of preferences universally.
Strategic Forgetting: The current “forget” mechanism (instructional override) is a blunt instrument. True adaptive memory requires strategic forgetting – the ability for the system (ideally with user guidance) to automatically background or decay information that is no longer relevant to the current context or the user’s evolving interests. This prevents cognitive overload and keeps the AI’s working memory focused and agile.
Unified & Inspectable Memory: The separation between `user_defined` (editable), `topic_memory` (not editable/visible), and the hidden retrieval mechanism creates fragmentation. A more robust architecture, would integrate these different memory types into a more unified, inspectable, and controllable whole, allowing users better insight and agency over the system’s knowledge base.
Moving towards these principles—transparency, contextual adaptation, strategic forgetting, and unified inspectability—would allow AI memory systems like ChatGPT’s to better align with human cognitive fluidity and create more natural, trustworthy interaction partners.
Conclusion
What this conversation ultimately highlighted wasn’t the power of memory—it was the importance of forgetting. Not forgetting as failure. Forgetting as design.
The system didn’t recall everything. It reactivated only what the moment allowed. Not because it couldn’t retrieve more, but because its memory model is shaped by what it believes it should care about, based on my “user profile”.
And that’s where things get interesting. Because remembering everything is easy. What’s hard—and essential for flexible, multi-context systems—is remembering the right version of you, at the right time.
Am I Julian the interface designer right now? Or am I Julian the traveler, the writer, the person just curiously asking about cultural history or something deeply personal?
In a system keyed to assume a stable user identity, those distinctions flatten. The model doesn’t know when to let certain traces go quiet. It assumes persistence where there should be conditional presence.
A well-designed memory system should be capable of not just retrieval, but withdrawal—stepping back when the current context doesn't support continuity. It should forget strategically in order to resist overfit. It should forget on your behalf.
The risk isn't that systems forget too much. It's that they remember in the wrong direction.
In my thinking (and writing) about Ephemeral Interfaces, this is a central theme: “State” isn’t a thing to be accessed—it’s a shape that adapts to intent. Strategic withdrawal—forgetting on the user’s behalf—is what lets that shape stay fluid. Not just mere data cleanup or tree pruning; conceptually this can be the engine of adaptation. It resists overfitting to past contexts, breaks path dependency, and protects fluid role-shifting, allowing the system to meet you here, now, not just where it last remembered you.
TL;DR
ChatGPT's memory uses editable user facts, auto-generated topic summaries, and a retrieval mechanism that can reactivate past context based on triggers but lacks transparency and metadata. While functional, its opacity and focus on a static user identity limit its adaptability and trustworthiness compared to more context-sensitive, controllable memory architectures.
The current system hints at what it feels like to work with more dynamic and adaptive interfaces, but transparent, context-aware adaptation remains a key challenge. Achieving truly fluid and trustworthy AI collaboration requires moving beyond opaque mechanisms and rigid identity constructs towards systems that embrace the contextual, adaptive, and ephemeral nature of human thought.